
Trying AI is the easiest thing you'll do all year. One useful prompt — a contract summarized, an email drafted, a spreadsheet untangled — and you have, technically, "used AI in your business." The hard part is the one nobody warns you about: getting AI to fit a process. To run part of how your company actually operates, day after day, without you babysitting it. That gap — between "I tried ChatGPT" and "AI runs part of how my business runs" — is where most owners get stuck, and it's the whole subject of this article. Used well, AI in business processes isn't a faster version of the automation you already know. It does a second, harder job: it keeps the way you run the business fitted to a reality that won't sit still.
Table of contents
- You run the business through a model
- The real enemy is drift, not missing cases
- What AI actually adds to business processes: automate, optimize, sense
- Making it measurable: the first-pass rate
- What this looks like in practice
- Where to start: the data layer, not the ERP
- The pitfalls — and the honest odds
- Frequently asked questions
You run the business through a model
Step back from the day-to-day and look at how your company actually runs. You don't manage every transaction by hand. You manage through a model of the business — a working abstraction made of people, processes, and systems, increasingly stitched together over a shared layer of data. The model is how a manager holds a company too big to hold in their head. It's the standard People–Process–Technology framework that has organized operations for decades; the live shift in 2026 is that practitioners now treat data as a fourth pillar in its own right, because that's where the other three meet.
Directing a business through a model is an old discipline, and each wave of tooling handed managers new instruments — the org chart, the standard operating procedure, the ERP, the dashboard. AI in the process layer is the newest of those instruments, and it's worth being clear that processes are one component of a wider AI transformation, not the whole of it. That's the one paragraph of history this article needs.
Here's where I'll be direct about where this comes from. Earlier in my career I sat in the business analyst's chair, drawing the diagrams that were the model — IDEF0 process maps, use-case specifications, the formal description of how work was supposed to flow. And I watched those diagrams go stale almost the moment the ink dried, because the business they described had already moved on. For a century, each tooling wave upgraded the systems lever and rigidified the process lever, while people quietly absorbed every exception the systems couldn't handle. AI is the first wave that reaches into the process and people layers directly — it can take on the exceptions that used to require a human to notice and resolve.
The real enemy is drift, not missing cases
The common diagnosis of why operating models fail is that they don't cover enough cases — "we didn't think of that scenario." That diagnosis is wrong, and getting it wrong is why so much process work goes nowhere. Analysts have always modeled variation. IDEF0, use-case diagrams, BPMN — these notations exist precisely to capture branches, exceptions, and alternate paths. Coverage was never the wall.

The real walls are two, and they're more stubborn. The first: a richer model explodes. Every exception you add multiplies the branches until the diagram is a wall-sized tangle nobody reads, let alone maintains. The second, and the one that matters most: a model is only accurate the moment you draw it. A business is a living thing inside a moving market. The day after you finalize the process map, a supplier changes terms, a competitor shifts pricing, a regulation lands, a customer behaves in a way your map didn't anticipate. Model and reality begin to drift apart. The gap widens quietly, and as it widens you lose two things: efficiency (work routes around the official process) and control (you no longer really know how the business runs).
Building a bigger, more detailed static model doesn't solve this — it just trades the unreadability problem for the staleness problem, and usually buys you both. This is the timeless management problem, and it has a name in disguise. The genuine innovation of Agile wasn't the rituals; it was shortening the time-step — smaller increments, faster feedback, less drift accumulated between corrections. Which raises the obvious question: what shrinks the fit-and-adjust loop even further?
What AI actually adds to business processes: automate, optimize, sense
The answer is not "a bigger, smarter model that finally covers everything." That's the old trap with more compute behind it. The answer is to keep the model deliberately simple and let AI watch the boundary — continuously comparing what's actually happening against what the model says should happen, and flagging where the two have pulled apart. Re-alignment becomes a steady, cheap activity instead of a periodic, expensive remodel. This has a mature name worth knowing once: process mining, or conformance checking — comparing real event logs against a normative model to surface deviations. Name it, then set the jargon down, because the useful way to think about it is simpler.
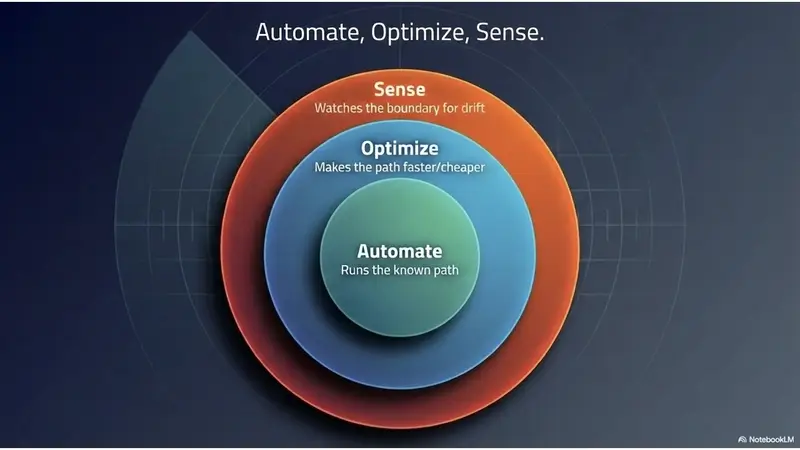
There are three things AI can do to a business process. We use this as our working lens:
- Automate — run the known path. This is table-stakes. Everyone sells it, and rule-based automation has done it for years.
- Optimize — make the known path faster, cheaper, or more accurate. Also well-trodden.
- Sense — notice when reality has stopped matching the path. This is the new one, and it's the load-bearing one, because sensing is what makes adaptation possible.
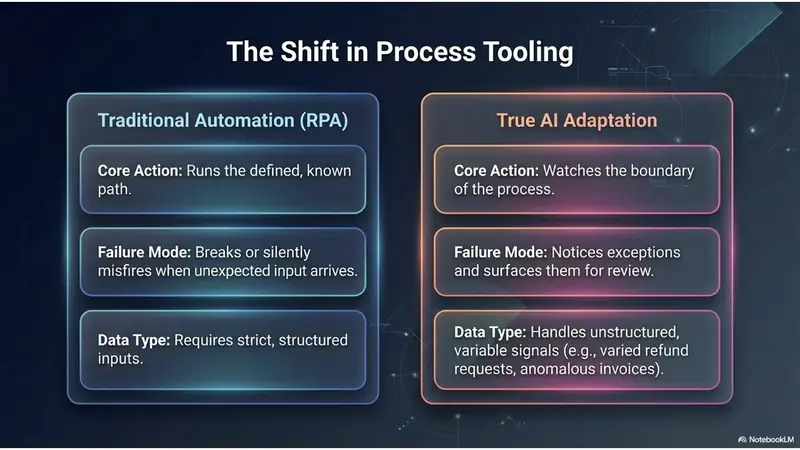
That third capability is where AI earns its name rather than rebranding what came before. A classic rule engine runs the path you defined; the moment something arrives that your rules didn't anticipate, it either errors out or quietly does the wrong thing. AI's contribution is handling the unstructured, variable signals of drift that a fixed rule engine can't catch — a string of refund requests phrased five different ways, an invoice that doesn't match any template, a pattern in the support queue that no one flagged. The rule engine runs the process. AI notices when the process stopped fitting reality.
Make it concrete. Picture accounts receivable. Automation matches incoming payments to open invoices and clears the easy ones — known path, known rules. Sensing is different: it's the part that notices a particular customer has quietly shifted from paying in 30 days to paying in 47, that a batch of invoices keeps failing to match because a field changed upstream, that a category of dispute is rising. None of that is a "case" anyone wrote a rule for. It's drift — and it's exactly the signal a fixed automation would step right over.
One honest boundary. Enterprise-grade process mining assumes a clean, structured event log most smaller businesses simply don't have. So the SMB version of this isn't an off-the-shelf conformance suite; it's a deliberately simple model plus AI watching a few processes that matter — which is exactly why the data layer (below) is the real prerequisite, not the software license. We go deeper on the affordable version in a follow-up.
Making it measurable: the first-pass rate
If sensing sounds soft, here's the instrument that makes it concrete: the first-pass rate, also called straight-through processing — the share of work that flows from start to finish without a human having to touch it. For invoice processing, order intake, or onboarding, top-quartile operations run 80% or higher. It's one number on the dashboard, not the whole story — but it's a clean readout of how well your model still fits reality. When first-pass rate slips, it means more work is falling out of the automated path and onto a person, which is precisely the drift signal you want to catch early.
Here's the distinction that matters. AI raises first-pass rate not by replacing your rulebook and not by absorbing every possible variation — that would just be the bigger-static-model trap again. It raises it by detecting the deviations a stale model would have silently dropped, and routing them to be handled or folded back into the model. The number goes up because less is quietly falling through the cracks, not because the machine now pretends to handle everything.
What this looks like in practice
Two examples from our own work, because borrowed research is no substitute for things we've actually built.
The first is Royal Finance, a loan broker whose hybrid chatbot cut operator workload by 60–70%. What makes it relevant here isn't the automation rate — it's the split. Deterministic rules run the regulated, high-stakes path (product qualification, matching, rates pulled straight from the database), and in production they handle 85% of inputs with no language model involved at all. AI agents take only the messy remainder: the free text where a customer types "three million" instead of tapping a button, or asks a question the rulebook never anticipated. That division is a conformance loop in miniature. The deterministic model owns the known path; the AI watches the boundary and handles the variation that falls outside it — and where it can't, it routes rather than guesses, because a wrong answer about a loan rate is not an acceptable failure.
The second example is closer to home: the AI agent that produces much of our own SEO content. Every draft it writes passes through a panel of automated critics that score it against a defined quality bar; drafts that drift below the bar get flagged and sent back. That critic gate is a conformance loop — a normative model (the quality bar) checked continuously against actual output (each draft), with deviations surfaced rather than shipped. Both examples are deliberate build-or-buy decisions; we've written separately on when to build a custom AI chatbot versus buy a platform, and on AI agents as the productized mechanism for exactly this kind of work.
And this example carries an important caveat that strengthens the point rather than weakening it. Writing is a generative task; its output is non-deterministic in a way that matching an invoice to a payment is not. You cannot run a generative process hands-off the way you can run a deterministic one. The critic gate exists precisely because of that — it's the sensing layer that catches drift, and then a human decides what each flag means. That is the mechanism, not a disclaimer: sensing plus human judgment is what makes non-deterministic AI safe to put into a real workflow.
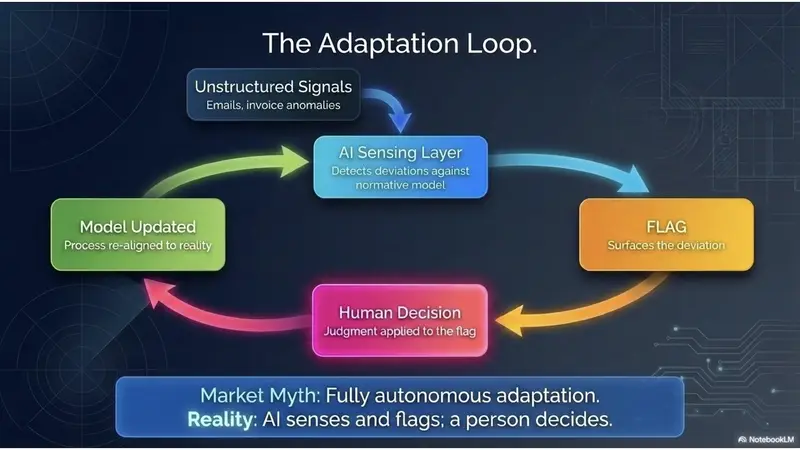
Which is the honest bound the rest of the market tends to skip. You'll hear "closed-loop" and "autonomous adaptation," as if the system both spots the drift and decides what to do about it. We design the opposite on purpose: AI senses and flags; a person decides. That's not the cheaper version of autonomy — it's the version that works, and it keeps the judgment where it belongs. (There's a second, separate "drift" the market loves to talk about — the AI model itself degrading over time. Real, but it's a different problem from the one in this article, and conflating the two is how a lot of AI pitches get sold. More on that distinction in a follow-up.)
Where to start: the data layer, not the ERP
Here's the part that decides whether any of this is reachable for a company your size, and it's the part most consultants get backwards. Sensing only works if AI can actually see the business clearly — and seeing clearly requires a consistent, structured data layer. That sounds like a reason to wait. It isn't.
You do not need to finish a digital transformation or install a big ERP before you start with AI. The market quietly sells the opposite — first the multi-year systems overhaul, then maybe AI — and for a mid-sized business that sequence is a trap that guarantees AI never arrives. What you actually need is a data foundation, not a data warehouse: enough clean, connected signal about one or two processes that genuinely hurt, so AI has something real to watch. Start there. One painful process, enough good data to see it, and the loop pays for itself before you've touched the rest of the company. This also fits the wider arc of an AI strategy: processes are one layer of it, not the whole of it.
Now the honest counterweight, because the reassurance is only half the truth. AI genuinely helps you absorb fragmented data — pulling signal from a CRM, a finance system, a pile of spreadsheets, and an inbox that were never designed to talk to each other. What it does not do is remove the need to store that data structured, consistent, and governed. Garbage in, garbage out has not been repealed. AI moves the labor of working with data; it does not abolish the discipline of organizing it. Point an AI at an ungoverned mess and you don't get insight — you get confident noise. This is not a footnote; it's the single most common reason pilots stall. The numbers back it: in one 2026 survey, 61% of chief data officers said higher data quality is what actually moves AI from pilot to production, and organizations with mature data governance reported roughly 24% higher AI-driven revenue.
The pitfalls — and the honest odds

A short list of the ways this goes wrong, drawn from the argument above:
- Don't build the giant static model. The thing that failed before will fail again, just slower and more expensively.
- Don't chase autonomy. Sensing is the AI's job; deciding is yours. A system sold as fully closed-loop is either overclaiming or quietly handing you the risk.
- Don't run AI on ungoverned data. No data foundation, no reliable sensing — just expensive guesses.
- Start simple and short-loop. A simple model that AI keeps fitted beats a perfect model that's already out of date.
And the honest odds, because this is hard and you should know it going in. The numbers people quote — and they get quoted as scare stories — are real, but they describe the difficulty of fitting, not the futility of trying. McKinsey's 2025 State of AI found 88% of organizations now use AI in at least one function, yet only a small share see meaningful financial returns. MIT's GenAI Divide study put a sharper number on it: roughly 95% of generative-AI pilots delivered little or no measurable P&L impact. But read the root cause, because it's the actionable part — the failures trace to a learning gap, the work of integrating AI into a real workflow, structure, and culture, not to the quality of the models themselves. The same research found that approaches built with specialized partners succeeded about three times as often as internal do-it-yourself efforts. That gap between trying and fitting is exactly the one this article opened with — and it's learnable, which is the entire reason to close it deliberately rather than by trial and error.
If you'd like a second pair of eyes on which of your processes is drifting hardest — and whether your data is in shape for AI to watch it — that's exactly where an AI consulting engagement starts. We map the drift before anyone writes a line of automation.
In follow-ups, we go deeper on the pieces this overview only gestured at: how to measure the fit between model and reality without an enterprise toolset, how the drift-sensing mechanism actually works for a business your size, and what the enterprise "autonomous" wave really means for a company that isn't enterprise-sized.
Frequently asked questions
Do I need an ERP or a finished digital transformation before starting AI? No. You need a data foundation, not a data warehouse — enough clean, connected data about one or two processes that genuinely hurt, so AI has something real to watch. The advice to finish a big systems overhaul first is, for most mid-sized businesses, a way to ensure AI never gets started. Begin with one painful process and enough good data to see it clearly.
What's the difference between automating a process and adapting it? Automation runs the known path — same input, same steps, same output, faster and cheaper. Adaptation keeps that path fitted to reality as reality changes: AI watches for where actual work has drifted away from the defined process and flags it, so you re-align continuously instead of waking up to a model that no longer describes your business. Automation is table-stakes; adaptation is the harder, more valuable job, and AI is the first affordable tool for it.
How is this different from RPA or ordinary rule-based automation? A rule engine executes the path you defined and breaks — or silently misfires — when something arrives that the rules didn't anticipate. AI adds the ability to handle unstructured, variable signals: it notices the exceptions and drift a fixed rule set can't catch, and surfaces them. RPA runs the process; AI senses when the process has stopped matching reality.
Does the AI decide what to do about the problems it finds? No — and that's by design. The AI senses drift and flags it; a person decides what each flag means and how to respond. "Fully autonomous, closed-loop" adaptation is mostly marketing; the version that actually works in a real business keeps human judgment in the loop. Sensing plus human decision is what makes non-deterministic AI safe to deploy on real work — and it's the difference between using AI in business processes and merely trying it.


